Hace unas semanas me encontré con un análisis de la evolución del valor de las acciones de las empresas que cotizan en la bolsa de Estados Unidos y la relación que tiene con las exposiciones (earning calls) que realizan sus representantes en cada cuatrimestre. En el informe se hace un análisis de lo que dice el representante sobre el estado actual de la empresa con un énfasis en las palabras que utiliza para obtener un “índice de positividad/negatividad” y compararlo con el valor accionario a lo largo del tiempo. Como el informe no provee los datos para reproducirla, decidí hacer un pequeño experimento con datos que pude recolectar de sitios de acceso público.
Para este proyecto obtuve datos de las earning calls cuatrimestrales realizadas en los últimos tres años por tres empresas de e-commerce: Mercado Libre (MELI), Ebay (EBAY) y Amazon (AMZN). La idea fue tomar estas empresas, obtener su valor por acción entre 2015 y 2017 y luego compararlo con un análisis similar al realizado por la empresa que mencioné anteriormente. Todó el código que utilicé está publicado en Github.
Por lo tanto, para llegar a la comparación final se necesita:
- Obtener los textos de las earning calls
- Identificar la negatividad de los textos
- Identificar la complejidad para leer cada texto
- Obtener los valores de las acciones de las empresas a lo largo del tiempo
- Comparar la negatividad de los textos con los precios de las acciones
¿Cómo obtuve los textos de las earning calls?
Obtener este tipo de dato no me resultó fácil, ya que el mundo financiero no es particularmente conocido por ser muy abierto y colaborativo. A través de Google encontré un sitio que tiene estos datos, acá el listado de los de Mercado Libre.
¿Qué es Sentiment Analysis (SA) y para qué sirve?
Básicamente SA es una forma de obtener la polaridad de un texto. La forma más común es la de categorizar a cada texto como positivo, negativo o neutral, pero también hay formas más complejas, como puede ser la extracción de emociones ligadas al texto (ira, desilusión, alegría, tristeza, etc). En este post vamos a usar la forma más común, que es la que usaron también en el informe original.
Para aplicar SA hay también diferentes enfoques. El enfoque más conocido es a través del uso de documentos manualmente categorizados, que luego son procesados usando Procesamiento del Lenguaje Natural para extraer características y finalmente son utilizados por un algoritmo de Machine Learning (de clasificación) para construir un modelo predictivo. Este modelo, una vez entrenado, podrá recibir nuevos documentos y predecir con cierto margen de error si se trata de algo positivo o negativo.
Pero hay formas de aplicar SA sin tener que entrenar un modelo de Machine Learning a partir de textos manualmente categorizados, aunque frecuentemente es una forma menos precisa. Una de estas formas fue la utilizada en el informe original y se trata de calcular la proporción de palabras negativas en cada texto.
¿Cuáles son las palabras negativas?
Para eso se usa algo parecido a un diccionario, donde cada palabra tiene asignada un sentimiento (entre otras cosas) de acuerdo a criterios que dependen de quien crea ese diccionario. Hay muchos de estos “diccionarios” dando vueltas, algunos gratis otros pagos, pero el que usaron en el análisis y que voy a usar también yo se llama “LoughranMcDonald_MasterDictionary” y lo pueden bajar desde el sitio web del creador bajo el nombre de “2014 Master Dictionary”. Si descargan el archivo se van a encontrar con un archivo de excel que en cada fila tiene una palabra y cada columna tiene características de esa palabra: si es positiva o negativa, cantidad de sílabas, entre otras. Este diccionario contiene palabras especialmente relacionadas al sector financiero y por eso es tan útil en este tipo de análisis.
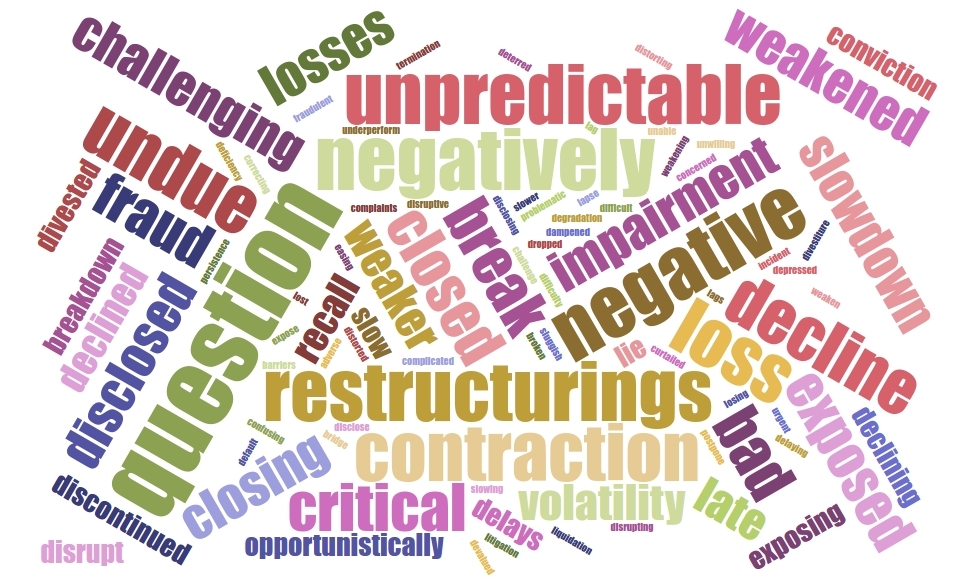
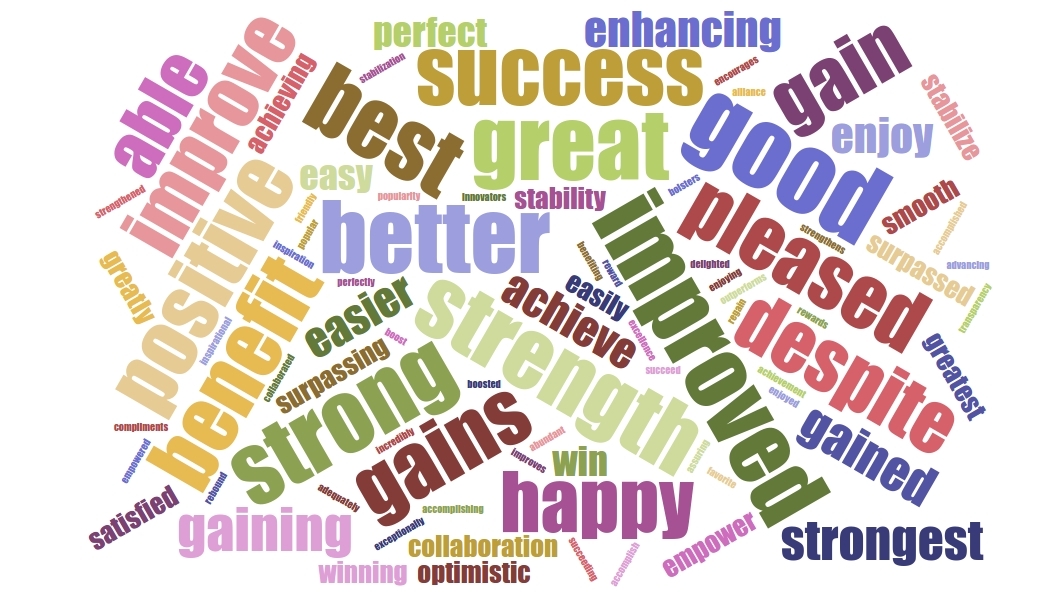
Para ilustrarlo a continuación les dejo dos imágenes de las palabras positivas y negativas más mencionadas en todas las earning calls (cuanto más grande la palabra, más veces apareció en los textos).
Nube de palabras negativas:
Nube de palabras positivas :
Calculando la “legibilidad” de un texto
Otro de los indicadores utilizados en el informe original para medir la positividad/negatividad de un texto fue el de calcular su “legibilidad” o readability en inglés. La suposición original fue que cuanto más compleja de entender sea una earning call, más probable es que a la empresa no le esté yendo bien porque el expositor recurre a palabras más complejas para “maquillar” la realidad. La legibilidad de un texto da una medida de cuan complejo es entenderlo. Hay muchísimas fórmulas para llegar a este valor pero en el informe se decidieron por el Gunning Fog Index que a través de la aplicación de su fórmula brinda una estimación de los años de educación formal que una persona necesita para entender el texto en la primer lectura. Si quieren saber la fórmula lo pueden leer en el link que les dejé antes.
¿Cómo obtener los valores de las acciones de cada empresa?
Para obtener estos valores lo que más necesitaba es de un sitio que provea estos datos a través de un API, y que sea gratis :). Un API para los que no están en el mundo del desarrollo de software es una forma de acceder a servicios de terceros a través de código, si no existiera un API con este tipo de datos la alternativa sería descargar una o varias planillas y luego procesarlas para obtener los datos, lo que demandaría bastante más tiempo.
Por suerte lo pude encontrar y si quieren usarlo pueden ir a la documentación del sitio y/o ver el código que publiqué en Github.
Comparando análisis de negatividad con la evolución en valor de las acciones de cada empresa
Llegó el momento de analizar todo el trabajo y finalmente ver si existe relación entre la negatividad de los textos de las earning calls y la evolución en el valor de las acciones de cada empresa. Tomé una de las tres empresas para mostrar un caso de ejemplo, el total lo pueden ver en github.
[table id=3 /]
[table id=5 /]
Conclusiones
Como ven en los números que mostré arriba para el caso de Amazon, la comparación no arroja resultados alentadores y por lo tanto no se pueden usar para ningún análisis posterior serio.
¿Por qué dan mal las comparaciones si en el análisis original llegaron a que si sirven?
Varias posibilidades:
- En el análisis original usaron datos de muchísimas mas empresas que yo y además hicieron las comparaciones por industria, no por empresa.
- El análisis original fue llevado a cabo por profesionales de varias disciplinas y cobran por ello. Este análisis lo hice yo en una semana y sólo con fines didácticos.
- Me equivoqué en algún lado y todavía no me di cuenta donde :P. Para eso compartí el código y cualquiera puede verlo y decirme si este fue el caso, no soy experto en este tipo de análisis de sentimiento así que hay chances de que existan errores en el procedimiento.
Recursos
- ¿Qué es el análisis del sentimiento?
- Naive Bayes Classification and sentiment – Speech and Language Processing (3er ed. draft) Dan Jurafsky y James Martin
- Informe original